How I use LLMs 在网上有着可能是「全网最硬核且通俗易懂的 AI 工具使用指南」的超高评价,作者 Andrej Karpathy 也是一位 AI 领域的大神:
- Eureka Labs 创始人,专注 AI 教育
- 前 特斯拉 AI 总监
- 前 OpenAI 创始成员与研究科学家
- 斯坦福大学计算机科学博士并且设计了斯坦福大学第一门深度学习课程
因此这个视频真的非常值得一看,尽管它长达两个小时。不过为了方便自己以后回顾,这里我也做了一份 TL;DR 的总结:
视频详细介绍了如何使用像 ChatGPT 这样的大语言模型,作者 Andrej Karpathy 讲解了 LLM 的实际应用和技巧。
他首先介绍了ChatGPT 的起源和发展,并概述了当前市场上各种 LLM。随后,他演示了与 LLM 的基本交互方式,强调了理解 Token 和上下文窗口的重要性。视频还探讨了LLM 的训练过程,包括预训练和后训练。此外,作者还展示了LLM 如何进行知识查询,并建议在不同主题之间切换时创建新的聊天,以及注意所使用的模型类型。更高级的功能如思维模型、工具使用(例如网页搜索)、深度研究、文件上传和分析、代码执行(包括高级数据分析和 Artifacts)以及在集成开发环境中使用 LLM也被涵盖。最后,视频还介绍了多模态交互,包括语音、图像和视频,以及提升用户体验的功能,例如记忆、自定义指令和 GPTs。
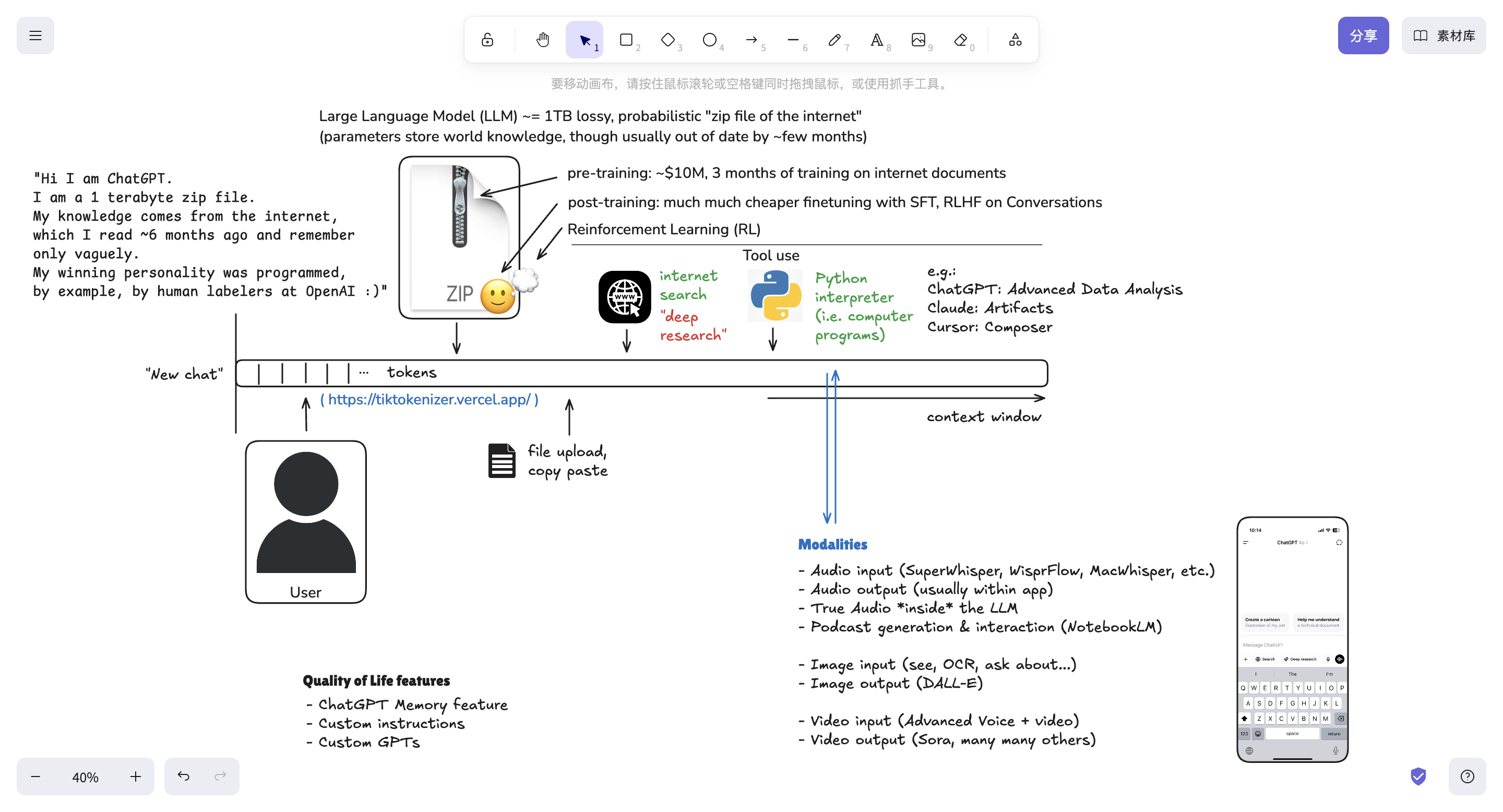
作者的白板画布
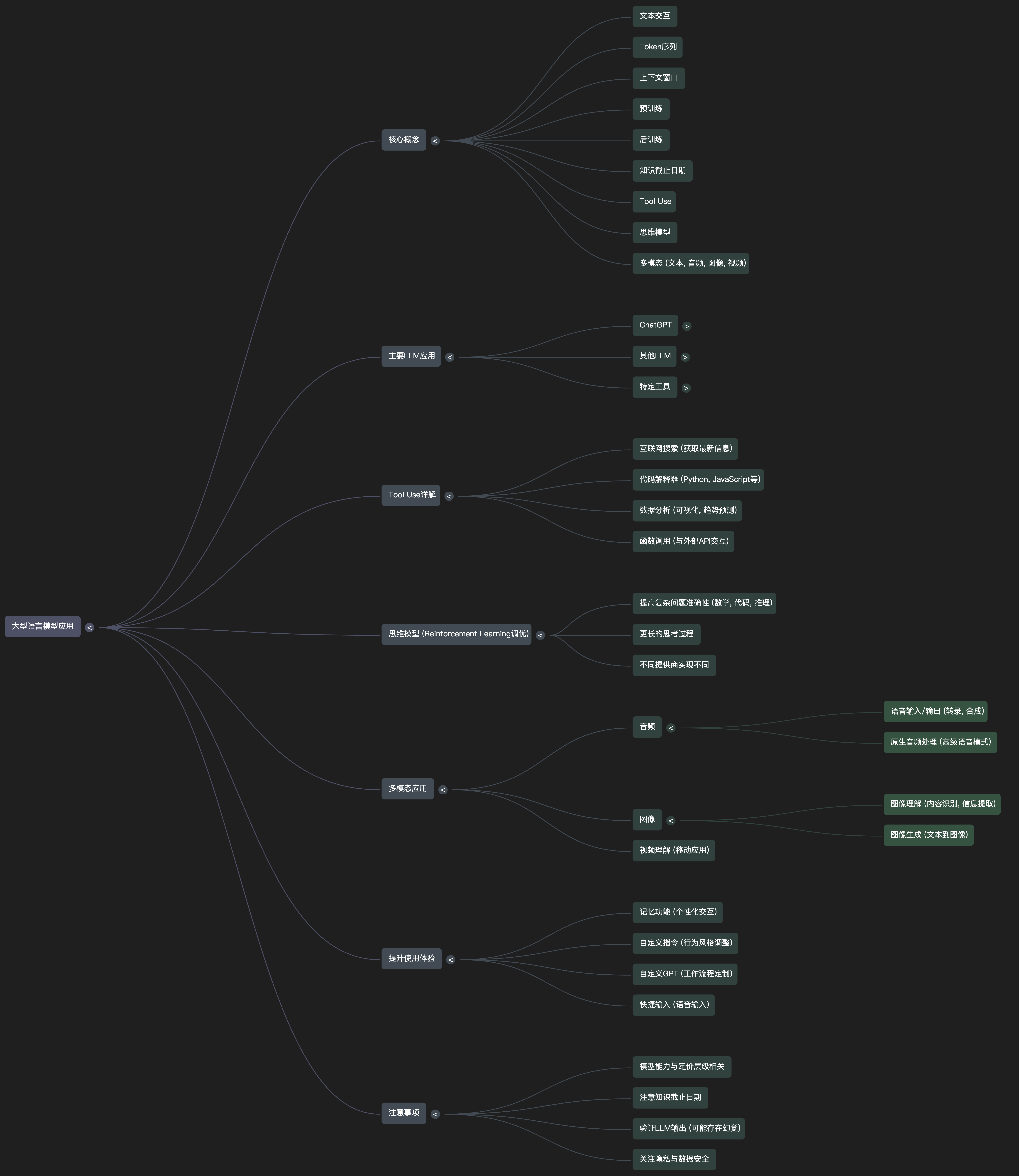
思维导图
干货总结
- Token 序列 (Token Sequence):这是 LLM 处理和生成文本的基础。无论是用户的输入(查询)还是模型产生的输出(回复),在底层都被切分成称为“tokens”的小文本块,并以一维序列的形式存在。Karpathy 使用 Tik tokenizer 这个工具来展示文本是如何被模型视为 token 序列的。
- 上下文窗口 (Context Window):上下文窗口是 token 序列的“工作记忆”。在一次对话中,用户输入和模型回复的 tokens 都会被保存在这个窗口中。模型可以访问上下文窗口内的所有 token,从而理解对话的上下文并做出连贯的回复。清空上下文窗口(例如通过点击“New Chat”)会重置 token 序列。Karpathy 强调上下文窗口是宝贵的资源,过多的不相关 token 可能会分散模型的注意力并增加计算成本。
- 模型训练 (Model Training):LLM 的训练主要分为两个阶段:预训练 (Pre-training) 和后训练 (Post-training)。
- 预训练是将整个互联网的数据切分成 token 序列,模型通过预测序列中的下一个 token 来学习世界知识,并将这些知识压缩到神经网络的参数中。这个阶段成本高昂且不常进行,导致模型存在“知识截止日期”。
- 后训练是通过人类标注的对话数据集来调整模型的行为,使其更像一个有帮助的助手,并形成特定的对话风格。 因此,Karpathy 将 LLM 比作一个存储了预训练知识(来自互联网)和后训练人格的“zip 文件”。
- 工具使用 (Tool Use):Karpathy 强调,默认情况下,LLM 本身是一个“封闭的实体”,没有计算器、Python 解释器或互联网浏览器等工具。为了克服知识截止日期和执行更复杂的任务,需要赋予模型使用外部工具的能力。视频重点介绍了互联网搜索作为获取最新信息的关键工具。当模型判断需要最新信息时,可以发出特殊的 token 来触发搜索,搜索结果会被加载到上下文窗口中供模型参考。Karpathy 还展示了 Python 解释器作为 LLM 进行数学计算和数据分析的工具。不同的 LLM 可能拥有不同的工具集成能力。
- 多模态 (Multimodality):视频介绍了 LLM 处理不同模态信息的能力,例如音频 和图像。关键在于,这些非文本数据也可以被转化为 token 序列。例如,音频可以被分解成频谱图并量化为音频 token,图像可以被分割成 patches 并量化为图像 token。这使得 LLM 的 Transformer 架构能够以统一的方式处理多种类型的数据。Karpathy 展示了 ChatGPT 的语音模式和图像识别能力。
- 思考模型 (Thinking Models):这类模型通过强化学习 (Reinforcement Learning) 进行了额外的训练,使其能够进行更深入的思考和推理,类似于人类解决问题时的“内心独白”。Karpathy 通过一个编程错误的例子展示了思考模型在复杂任务上可能具有更高的准确性,但思考过程可能需要更长的时间。
- 自定义 GPTs (Custom GPTs):这是一个允许用户通过自然语言指令创建特定用途的 LLM 版本的功能。用户可以定义 GPT 的行为、知识和能力,并保存下来以便重复使用,从而节省了重复编写提示词的时间。Karpathy 主要将其应用于语言学习任务,例如词汇提取和详细翻译。
总而言之,Karpathy 的视频深入浅出地介绍了 LLM 的核心概念及其在实际应用中的各种方式。他强调理解 token 序列、上下文窗口和模型训练是理解 LLM 工作原理的基础。同时,他也展示了如何通过 工具使用和多模态扩展 LLM 的能力,以及 思考模型和自定义 GPTs 等更高级的功能。视频还强调了 LLM 的一些局限性,例如知识截止日期和潜在的“幻觉”,提醒用户在使用时保持批判性思维。最后,Karpathy 还分享了许多提高 LLM 使用效率的技巧和工具,例如语音输入和不同的 LLM 应用选择。
最后,TL;DR 内容较干,建议有时间还是观看原视频学习,这样才能更好的消化理解。